The Limitations of Prisma as an ORM for Analytics
While Prisma’s engine is crafted in Rust, a language lauded for its performance and safety features, the efficiency and speed of queries are not solely determined by the underlying language.
 In recent years, Prisma has gained popularity as an Object-Relational Mapping (ORM) tool, providing developers an efficient and intuitive way to interact with databases. While Prisma is well-suited for many applications, there may be better choices when creating analytics solutions. In this article, we will explore the limitations of Prisma in the context of analytics and highlight why alternative solutions may be more appropriate.
In recent years, Prisma has gained popularity as an Object-Relational Mapping (ORM) tool, providing developers an efficient and intuitive way to interact with databases. While Prisma is well-suited for many applications, there may be better choices when creating analytics solutions. In this article, we will explore the limitations of Prisma in the context of analytics and highlight why alternative solutions may be more appropriate.
While Prisma’s engine is crafted in Rust, a language lauded for its performance and safety features, the efficiency and speed of queries are not solely determined by the underlying language. The crux lies in the implementation of the process that translates Object-Relational Mapping (ORM) queries into SQL statements. Prisma, despite its Rust foundation, faces challenges in this crucial aspect. Proficiency in transforming queries is pivotal for optimizing database interactions. If Prisma falters in this transition from ORM to SQL, it can undermine the overall performance, rendering the touted advantages of Rust less impactful in practice. Therefore, the success of a database engine is contingent not only on the choice of language but also on the adeptness in query transformation, an area where Prisma may need refinement.
Performance Concerns Prisma excels in generating optimized queries for common CRUD operations. For straightforward database interactions, the generated SQL queries are often efficient. However, the optimization might vary when dealing with complex queries or large datasets.
Lack of basic SQL features when it comes to analytics
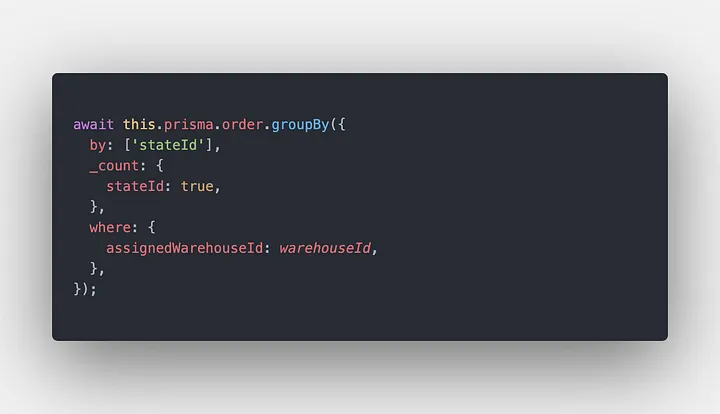
In the above example, I group by the order state to aggregate info about the order in a specific state what makes Prisma stupid is that it does not support include or select to get the name of the state id
Bad and fast solution
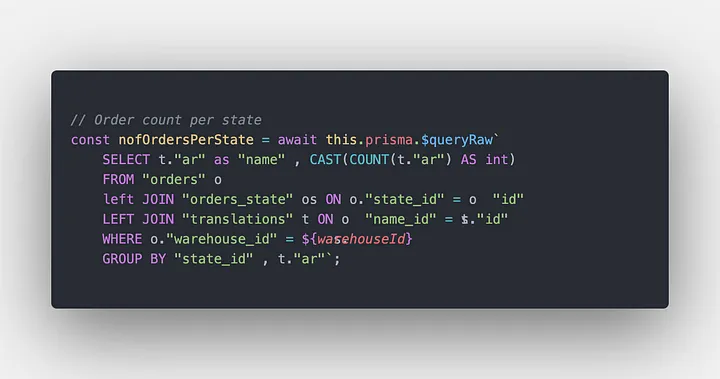
To solve this problem I need to make requests on the DB to fetch the state's name which will be pricy if the DB provider accounts the IO to the DB. Reducing the IO to the DB could result in fewer monthly payments by thousands of dollars
Good but time-consuming solution (MUST)
the best solution is to rewrite the function in raw SQL. which will be very efficient and in one call to the DB.
Badly even Prisma client $queryRaw is not optimized and dummy sometimes you write valid SQL queries but they don't execute
the best solution is to rewrite everything in raw SQL and not use Prisma you could use the pg library for interacting with PostgreSQL DB for example
Fake type safety

Prisma may support a lot of type safety but this kind of type safety is misleading and make you encounter a lot of problems at the run time.
even if the file is written in 1TS and all the required interfaces and types are generated the TS compiler wouldn't complain about the distinct argument not existing on the count function And an exception will be thrown at the run time
The caveats lot of include and select statements

Prisma’s approach to database interactions can have ramifications on the Input/Output (IO) performance of the underlying database provider. Unlike some database engines that optimize queries for efficiency, Prisma may make multiple calls to the database for join operations, rather than executing a single comprehensive query. This choice can potentially lead to increased IO demands, particularly when dealing with numerous requests simultaneously. In scenarios where tens or hundreds of requests are made concurrently, the cumulative effect of multiple individual queries can strain the database’s resources, resulting in slower response times and a potential increase in costs for the database provider. The challenge lies not only in the volume of queries but also in the fragmented nature of these requests. Optimizing the orchestration of joins and refining the query execution strategy could be areas where Prisma might benefit from improvement to mitigate the impact on database IO and enhance overall performance.
Conclusion
In conclusion, while Prisma presents itself as a promising database toolkit with the efficiency of Rust underpinning its engine, caution is advised when considering its integration into substantial projects. The potential IO strain caused by multiple database calls, especially in scenarios involving intricate join operations and concurrent requests, may pose challenges for scalability and performance optimization. In more extensive and resource-intensive projects, where database efficiency is paramount, alternative solutions with a proven track record of handling complex queries and large-scale operations might be more prudent. It’s essential to weigh the advantages of Prisma against the specific demands of a project and consider alternatives that align more seamlessly with the scalability and performance requirements of substantial endeavors.